Research Update
One of the things listed as missing in the previous post was the complete lack of auto-learning. Well, with quite a bit of thought, and code, I have a basic version working. The idea is based on the old line fire together, wire together, which we are going to call associative sequence memory.
So, at designated times, take a snapshot of the currently active synapses, check if they activate an existing neuron, and if not, then store that pattern into a new neuron/synapse pair. Then later down the track we can prune neurons that are below some given activation threshold.
What does designated times mean? Well, in the general case, I don’t know, but in the current case it is triggered by punctuation characters. We have two relevant neuron flags that implement this: init store buffer flag and store buffer flag. Where, the init flag clears the buffer, and starts a delay counter. The store flag uses this delay counter to only consider synapses that have fired in the last few time steps. Then it checks if the currently active synapses already trigger a neuron, if so, do nothing. If not, then wire in a new neuron. By taking delay into account, this system easily learns sequences. Eg, in the below example, words separated by punctuation characters.
To help with this, we have some required pieces:
- activation count each time a neuron is activated, increment its activation count.
- prune removes neurons and their corresponding synapses if they have been activated less than some threshold. Ie, irrelevant neurons.
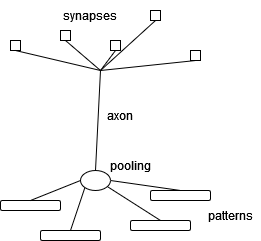
- layers to keep the
active synapses pattern clean, we use the idea of layers. The initial neurons are in layer 0, then the neurons that take their input are in layer 1, and so on for higher layers. In the example below we only consider active synapse patterns for layer 1, and store the resulting neurons and synapses in layer 2.
- auto delay synapses instead of hand-wiring in synapses for all the different delays, we use
auto delay based on the synapse name. Eg: some synapse S0 D3 is taken to be the synapse some synapse S0 with a delay of 3.
- active synapses returns a list of active synapses at the current time step, and in the given layer, with a max delay count.
- test pattern tests if the given pattern invokes a known neuron, usually used in combination with
active synapses
example of active synapses
For example, the word “Hello” has the following active synapses, for layer 1, and a max delay of 4
['print capital h S0 D4', 'print lower e S0 D3', 'print lower l S0 D1', 'print lower l S0 D2', 'print lower o S0 D0']
test script
Written with the help of ChatGPT I have a bash script test_scripts.sh that runs through all my testing python scripts, checks if any of them raise exceptions, and then stores the results in a date and timed log directory. We had to take this approach because the script outputs were too large to wire in to traditional unit-testing approaches (that I know of). A further benefit is I can choose a date/time and check the output of any of my scripts at that time.
ToDo
- fix the test for existing neuron code. I’m not yet sure why it is broken.
- implement layers of these auto sequence learning. So layer 2 would be individual words, made up of characters, and layer 3 would be phrases, made up of sequences of learned words.
- generalize the idea of punctuation characters to other sequence types. Ie, when is a good time to invoke the
store buffer flag?
- come up with examples other than learning characters into words
- come up with ideas for other auto-learning mechanisms
- update the project README
Project GitHub
The full code is available on my GitHub.
Here is auto-learning in action
In this example we feed in the sequence “Hello, Hello!” to our system. This sequence was chosen so that the first “Hello” would store a pattern into a neuron/synapse, and the second “Hello” would trigger that neuron, but without storing its own pattern. This only half worked, because our test neuron code is currently broken, and hence the code stored the pattern twice (N0 and N2). Note that N1 is an empty pattern triggered by the sequence of punctuation characters ", ".
We note that the output of this system is
stored sequence: Hello
Hello, Hello!
The first line is the output from our new neuron N0 (triggered by the second occurrence of the “Hello” string), and the second line is the output from our full input sequence “Hello, Hello!”.
Here is the full output of our testing script
$ python3 testing_system_print_sequence.py
Let's implement 'Hello World!' in a print sequence system:
To store:
name: N0
delay: 5
layer: 1 ['print capital h S0 D4', 'print lower e S0 D3', 'print lower l S0 D1', 'print lower l S0 D2', 'print lower o S0 D0']
neurons: []
buffer: Hello
Will store a neuron and synapse!
Neuron: N0
layer: 2
activation count: 0
pooling: <function pooling_or at 0x7febc73afea0>
params: {}
patterns: 1
0 trigger: <function trigger_dot_product_threshold at 0x7febc73afe18>
0 params: {'threshold': 5}
0 [1, 1, 1, 1, 1]
0 ['print capital h S0 D4', 'print lower e S0 D3', 'print lower l S0 D1', 'print lower l S0 D2', 'print lower o S0 D0']
axon: []
Synapse: N0 S0
source axon: N0
source layer: 2
type: <function synapse_delayed_identity at 0x7febc73af730>
params: {'sign': 1, 'delay': 0}
action: <function action_println at 0x7febc7358158>
action params: {'s': 'stored sequence: Hello'}
spike history: []
To store:
name: N1
delay: 0
layer: 1 []
neurons: []
buffer:
Empty pattern!
To store:
name: N2
delay: 5
layer: 1 ['print capital h S0 D4', 'print lower e S0 D3', 'print lower l S0 D1', 'print lower l S0 D2', 'print lower o S0 D0']
neurons: []
buffer: Hello
Will store a neuron and synapse!
Neuron: N2
layer: 2
activation count: 0
pooling: <function pooling_or at 0x7febc73afea0>
params: {}
patterns: 1
0 trigger: <function trigger_dot_product_threshold at 0x7febc73afe18>
0 params: {'threshold': 5}
0 [1, 1, 1, 1, 1]
0 ['print capital h S0 D4', 'print lower e S0 D3', 'print lower l S0 D1', 'print lower l S0 D2', 'print lower o S0 D0']
axon: []
Synapse: N2 S0
source axon: N2
source layer: 2
type: <function synapse_delayed_identity at 0x7febc73af730>
params: {'sign': 1, 'delay': 0}
action: <function action_println at 0x7febc7358158>
action params: {'s': 'stored sequence: Hello'}
spike history: []
stored sequence: Hello
Hello, Hello!
Neural System: example sequence system
--------------------------------------
Sources:
#OFF#: 0 <generator object source_off at 0x7febc73b2678>
#ON#: 1 <generator object source_on at 0x7febc73b26d0>
#INIT#: 0 <generator object source_init at 0x7febc73b2728>
#ALT-1#: 1 <generator object source_alt_N at 0x7febc73b2780>
Channels: ['!seq-0!', '!seq-1!', '!seq-10!', '!seq-11!', '!seq-12!', '!seq-13!', '!seq-14!', '!seq-2!', '!seq-3!', '!seq-4!', '!seq-5!', '!seq-6!', '!seq-7!', '!seq-8!', '!seq-9!', '#ALT-1#', '#INIT#', '#OFF#']
Modules:
Module: sequence module
delay counter: 20
inputs:
#INIT# -> "init flag" history: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
#ALT-1# -> "carry flag" history: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
#OFF# -> "off flag" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
outputs:
"0 neuron S0 delta" -> !seq-0! history: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"1 neuron S0 delta" -> !seq-1! history: [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"2 neuron S0 delta" -> !seq-2! history: [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"3 neuron S0 delta" -> !seq-3! history: [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"4 neuron S0 delta" -> !seq-4! history: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"5 neuron S0 delta" -> !seq-5! history: [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"6 neuron S0 delta" -> !seq-6! history: [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"7 neuron S0 delta" -> !seq-7! history: [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"8 neuron S0 delta" -> !seq-8! history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"9 neuron S0 delta" -> !seq-9! history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
"10 neuron S0 delta" -> !seq-10! history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
"11 neuron S0 delta" -> !seq-11! history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
"12 neuron S0 delta" -> !seq-12! history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
"13 neuron S0 delta" -> !seq-13! history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
"14 neuron S0 delta" -> !seq-14! history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
Module: print symbols module
delay counter: 4
inputs:
!seq-0! -> "init store buffer flag" history: [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-0! -> "use capitals flag" history: [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-0! -> "print h" history: [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-1! -> "print e" history: [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-2! -> "print l" history: [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-3! -> "print l" history: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-4! -> "print o" history: [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-5! -> "print ," history: [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-5! -> "store buffer flag" history: [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-6! -> "init store buffer flag" history: [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-6! -> "print " history: [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-6! -> "store buffer flag" history: [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-7! -> "init store buffer flag" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-7! -> "use capitals flag" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-7! -> "print h" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-8! -> "print e" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-9! -> "print l" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
!seq-10! -> "print l" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
!seq-11! -> "print o" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
!seq-12! -> "print !" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
!seq-12! -> "store buffer flag" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
!seq-13! -> "init store buffer flag" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
!seq-13! -> "flush buffer flag" history: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
outputs: